
はじめに
オープンワーク株式会社23年度新卒エンジニアの室永です。
5月31日から6月2日までの3日間、新卒1年目エンジニア向けのAWS研修に参加してきました(AWS触ったことが無い人でも付いていけるレベル感です)。 aws.amazon.com
去年の記事もあるので是非合わせて御覧ください。 techblog.openwork.co.jp
AWS JumpStart 2023 for NewGrads 設計編 概要
ざっくりですが流れとしては以下です。
- 参加前に講義動画を4時間分視聴(非常に分かりやすかったです)
- Webの仕組み基礎・AWSの各サービス・アーキテクティングの基本講義
- AWSの各サービス体験
- AWSでのアーキテクチャ考案グループワーク
以下、講義内容について要点をまとめます。
講義概要 − アーキテクティングの基本
ユーザーが100人のフェーズ
以下のような構成で十分です。

AWSを利用する場合は以下のようになります。
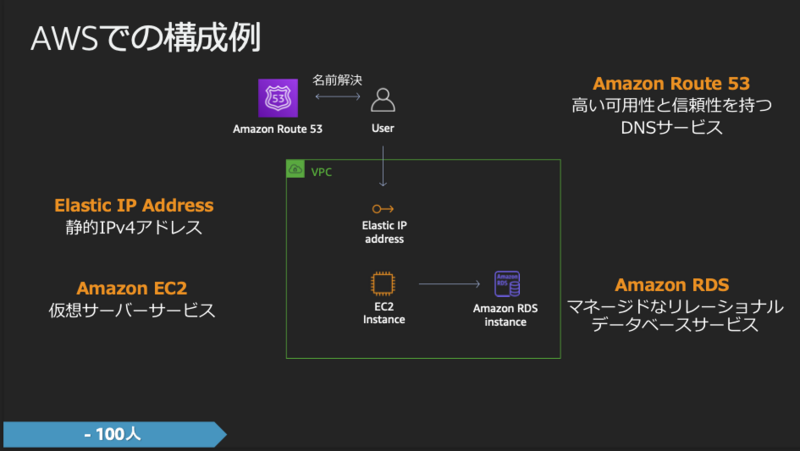
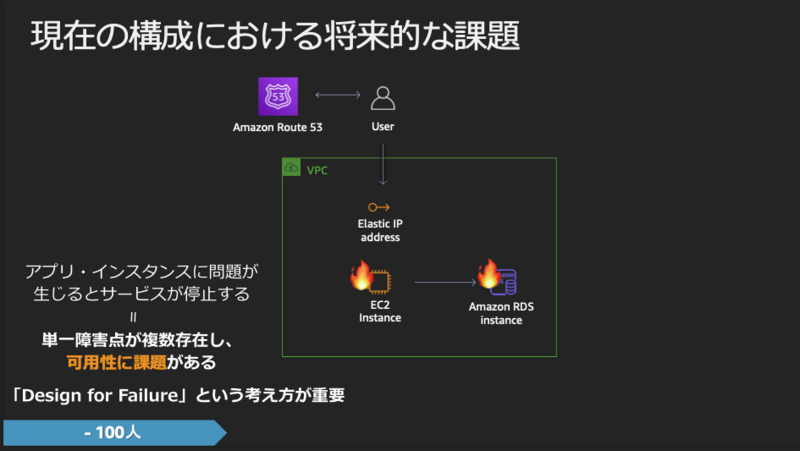
社内100人程度が使用するサービスであればこのような構成で十分ですが、将来的に以下のような課題があります。
- 単一障害点(Single Point Of Failure:SPOFのことで、その単一箇所が働かないとシステム全体が障害となるような箇所)がある
- スケールアップ(サーバの性能を向上させる)では限界がある
- スケールアウト( サーバの台数を増やす)の方が現実的
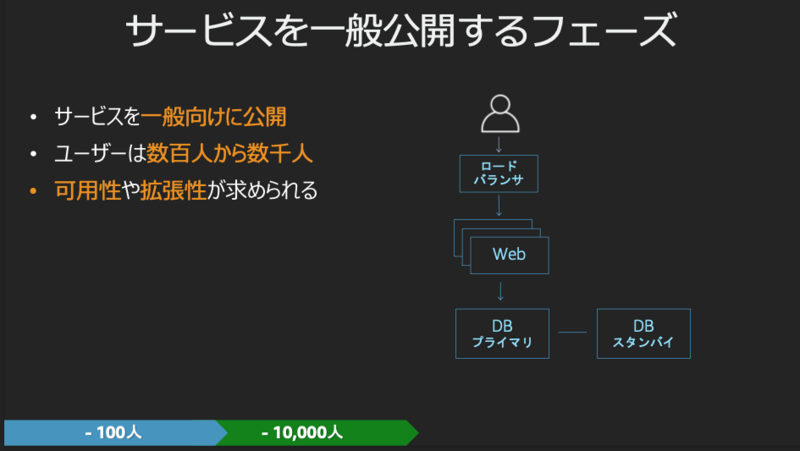
ユーザーが1万人のフェーズ
前述の課題を踏まえ、以下のような構成が考えられます。
- ロードバランサで負荷分散
- Webサーバのスケールアウト+随時ヘルスチェックで単一障害点を解決
- プライマリDBとスタンバイDBの利用+Write/Read専用DB
- DBの単一障害点を解決
AWSを利用する場合は以下のようになります。
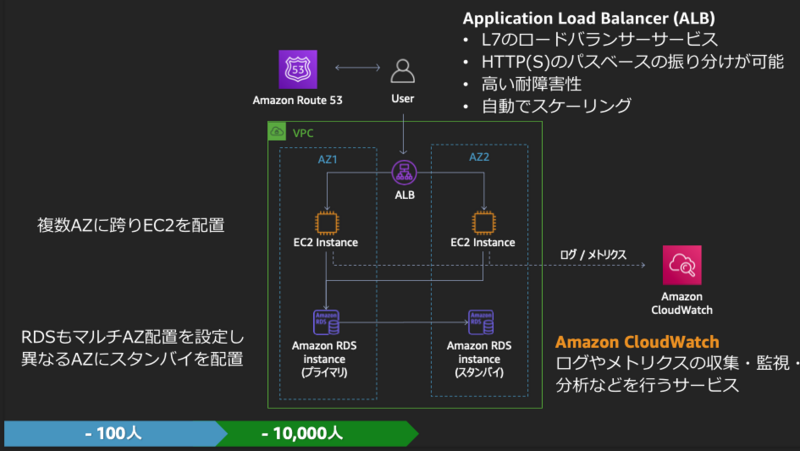
このような構成でも以下のような将来的な課題が考えられます。
- サーバ台数増加によるサーバ管理コスト増加
- DBへのクエリ量やデータ量増加によるDB読み書き負荷増大やレスポンス速度低下
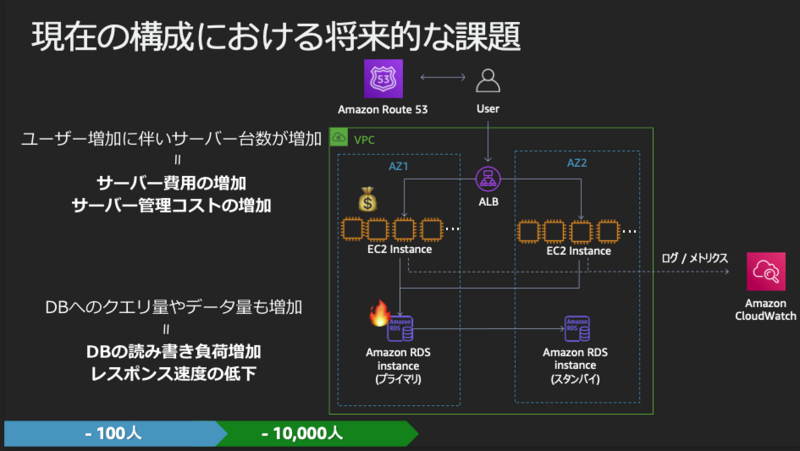
ユーザーが100万人のフェーズ
大規模ユーザーでもある程度運用可能な構成です。
- CDNとストレージで静的コンテンツの読み込み高速化
- プライマリDBに加え読み込み専用のリードレプリカを用意する
- 頻繁に利用されるデータ(キャッシュ、セッションなど)をインメモリキャッシュで高速化

AWSを利用する場合は以下のようになります。

このようなアーキテクチャでも将来的な課題や改善点はまだまだあります。
よって、計測や分析によって課題や改善策を見つけ改善を行うサイクルを回すと良いと思います。


重要指針
- 大規模ユーザに対するアーキテクチャはひとまずこの図をベースに考えるのが良い
- 明らかに発生しそうな課題を解決できる範囲でシンプルなアーキテクチャが好ましい
- アーキテクチャが複雑だと運用、改善コストが大きい
- 追加要件・当初見えなかった課題などが発生した場合に必要な要素を追加したりする
アーキテクチャまとめ
求められる要件は機能要件だけではなく、非機能要件も重要です。
- 機能要件 = アプリの機能、ビジネスロジックなど
- 非機能要件 = 可用性、スケーラビリティ、パフォーマンス、運用、セキュリティなど
とはいえ、すべてを完璧に実現するのは難しいので以下の観点で考え、そのサービスで許容できる基準を設定し、その基準を満たすような設計を目指す(のが良さそう)です。
- どれほどの 信頼性 を求めるのか
- どれほどの スケーラビリティ・パフォーマンス を求めるのか
- 効率よく 開発・運用 を行えるのか
- コスト の最適化はできているか
- セキュリティ観点 での検討
各非機能要件の改善例です。
- ロードバランサでの負荷分散
- データセンターレベルでの障害を回避するため複数データセンターを活用
- フェールオーバーとレプリケーション利用によるDB障害回避
- リードレプリカの利用によるパフォーマンス向上
- バックアップ戦略の策定
- スケールアウト可能な構成にしてオートスケーリングなども併用
- インメモリデータストアによう頻用データ処理の高速化
- 静的コンテンツのキャッシュ化
- メトリクスでのリソース監視やログ収集・活用
- CI/CDの活用によるリリース作業の安全化
- インフラのコード化によるインフラ構成の可視化や安全化
- コスト概算による不要サービス削減
- リスク分析による保守範囲の検討
OpenWorkでのアーキテクチャ例
以下のような記事もあるので是非合わせて御覧ください。 techblog.openwork.co.jp
以下はOpenWorkの本番環境の簡易アーキテクチャ図です。
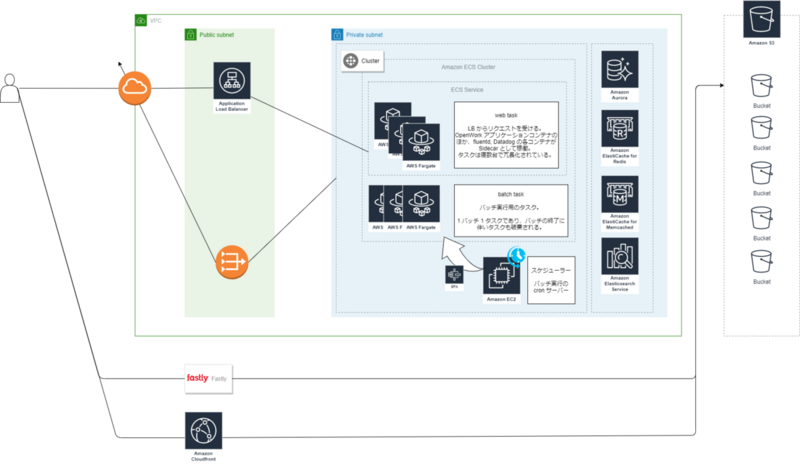
ロードバランサによる負荷分散、CDNで静的コンテンツのキャッシュ、インメモリキャッシュによる高速レスポンス、オートスケーリングや複数DBによるパフォーマンス・スケーラビリティ向上など、上記の100万人規模のアーキテクチャと基本的な部分は一緒ですね。
上記の図には書かれていないですが、弊社はTreasureDataやDataDogなども活用しているため、本来は以下のようなサービスも存在します。
- 裏側でバッチ処理をしたい → Webコンテナとは別にバッチコンテナを作成
- ユーザーのトラフィック分析をしたい → TreasureDataと連携してログ送信
- リソース監視やエラーログを保持したい → DataDogと連携してメリトリクス
基本の構成図に自社のビジネス要件や非機能要件を満たす上で必要なサービスや要素を付け足すイメージかと思います。
講義概要 - サーバーレス
サーバーレスとは
- サーバーが無いわけではなく、サーバーの運用や保守などを考慮しなくて良い構成です。
- カスタマイズ性は少ないですが、ビジネスロジックやアプリコードさえあればエンドユーザーに比較的少ない工数で価値を届けることが可能です。

EC2(仮想サーバ)とLambda(サーバレス)の比較です。
- サーバ管理や用意が不要
- 自動でスケーリングされる
- 少ない工数で価値を届けることが可能


AWSの各サービス体験
以下は本研修で触ったサービス一覧です。非常に多くのサービスに無料で触れることができて良かったです。
- Amazon VPC
- インターネットゲートウェイ
- パブリックサブネット/NATゲートウェイ
- プライベートサブネット
- EC2
- セキュリティグループ(ファイアウォール)
- ALB(Application Load Balancer)
- RDS
- Write/Read
- Amazon ECS + AWS Fargate
- CloudWatch
- CloudShell
- CloudFormation
- Systems Manager
- AWS Lambda
- Amazon API Gateway
- Amazon DynamoDB
- Amazon Translate

アーキテクチャ考案ワーク 成果物
基本課題と応用課題にそれぞれ個人ワークとグループワークで取り組みました。
課題はどちらも、AWSを利用したWebサービスのアーキテクチャ図考案です。
基本課題
作成したアーキテクチャ図:ベースの考え方は基本図とほぼ同様です。
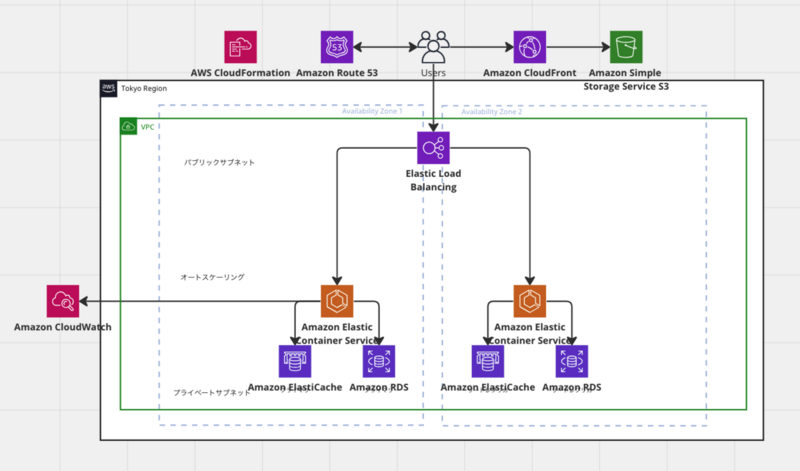
工夫点:
- 外部からセキュリティ脅威のためにWAFでファイヤーウォールを設置
- 長期利用しない静的コンテンツのためにS3 Galcierの併用でコスト削減
- CloudWatchによるメトリクス
- 夕方にアクセス増になることが分かっているため、冗長化ではなくFargateによるAuto Scalingを利用
- 大量トラフィックが予想されるカート機能にDynamoDBを利用することで速度向上
- Cognitoを利用することで実装工数削減とユーザー認証のセキュリティ向上
- CodeCommit CodePipeline CodeDeployによる自動CI/CD・デプロイ
- 商品画像など静的コンテンツ利用のためにCloudFrontやS3を利用
- Dockerによるコンテナ開発のため、ECSコンテナを利用
- 頻繁に利用するデータ読み書きのためにElastiCacheを利用
- DBの読み書きの負荷分散のためにリードレプリカを利用
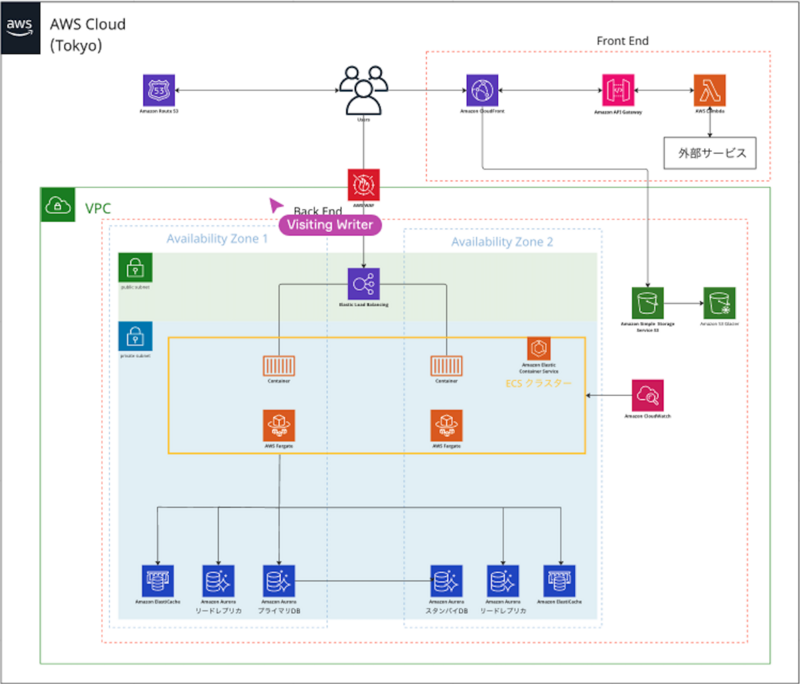
応用課題
テーマ:基本課題に特定の機能を追加したアーキテクチャ構成図の作成
作成したアーキテクチャ図:


工夫点:
- 自動でCI/CDラインが走るように
- AWS CodeCommitではなくGithubを利用しコスト削減
- QuickSightを利用
- 構造化データからは直接取得
- 非構造化データのS3からはAthenaでクエリ取得
- DataPipelineでデータを整形
- ログをRedShitに蓄積
- RedShiftの分析用の更新を検知したらPersonalizeでおすすめ分析
色々追加しましたが、AWSの運営側の方に最後に提示していただいたアーキテクチャ例はもっとシンプルなものでした。
必要以上に欲張ってあれもこれもと追加するとコストがかかったり保守が大変だったりすることもあるので、まずは最小限のアーキテクチャを構成し必要になったら都度追加する方針が良いと思います。
講義で紹介されたので読みたい記事(絶賛積読中...)
1⼈から1000万⼈までの道のり:AWSにおけるスケールするインフラ設計とは?
最後に
学べたこととして、アーキテクチャの基礎や設計時に気をつけるべきこと、AWS知識(なんとAWSサービスは200種類以上もある!)や使い方はもちろんですが、「エンジニアは実装だけして動けば良い」というわけではなく、サイトの品質を落とさないか?ユーザーが快適に利用できるか?運営側のコストは大丈夫か?追加の開発や保守は容易か?などの 非機能要件が非常に大事 だということを改めて再認識できたことが一番の学びだと思います。
アーキテクチャや大規模サービスのアーキテクチャについて考えたことはあまり無かったので非常に楽しく良い経験になりました!
この記事を読んでオープンワークに少しでも興味を持った方は、ぜひ採用サイトを覗いていただけると嬉しいです!