インフラチームの小川 (@tsubasaogawa) です。最近は枕を高くすることにはまっています。
よくある話ですが、昨年末、データベース (Aurora) に保存されているレコードを DWH の TreasureData に送信するという案件がありました。いくつか方法が考えられますが、今回は Embulk を ECS の Fargate で動かすことで対応をしてみました。
Embulk?
https://github.com/embulk/embulk
データ転送をバッチ的に行ってくれるツールです。プラグインで入出力先を拡張できるのが特徴で、今回は embulk-input-mysql + embulk-output-td を利用しています。
構成
下図のような構成をとりました。
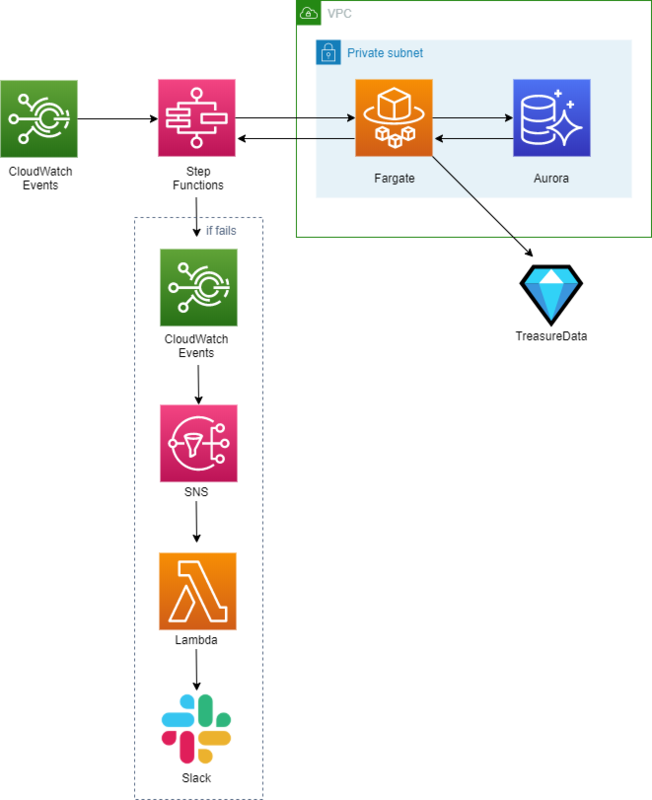
CloudWatch Events
cron() を記述し、スケジューラ実行されるようにしています。(誰もが通る道ですが) 記法については
- 一般的な cron と異なり項目数が 6 個あること (最後に Year がある)
- UTC であること
Step Functions
下記記事にある通り、Fargate を Step Functions で扱うメリットが数多くあり、採用しています。 https://blog.tkzwtks.net/entry/2018/12/22/191530
記事の内容ともかぶりますが、個人的に良いなと実感しているのは以下 2 点です。
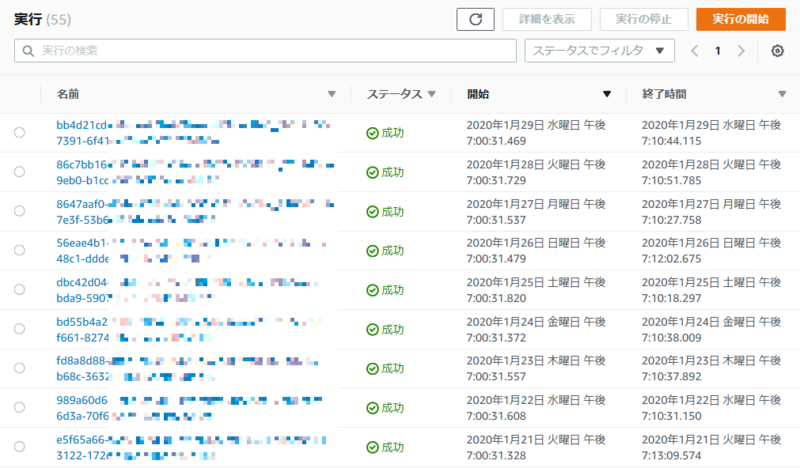
- タスクの成功/失敗履歴を一覧で確認できる
- マネジメントコンソールにおけるタスクの手動実行が比較的楽
- Fargate 直だと、デプロイ先 VPC やセキュリティグループなど初期設定をポチポチ選択しなければいけない
- Step Functions を経由させると、ステートマシンに初期設定を記述しておくことができるため、その分手間やオペミスのリスクが減る
今回、Step Functions で Fargate を呼ぶステートマシンを 2 本作成しました。
- 日次処理用
- 複数のテーブルを順番にエクスポートする
- 手動実行用
- 引数で与えられたテーブルをエクスポートする
後者のステートマシンの中身は以下のようになっています。ただ 1 本の Fargate を実行するだけなのでシンプルです。(実際は、複数の Fargate/Lambda などを直列/並列実行したり、ループさせたり、条件分岐したり色々できます)
{ "Comment": "Run data sync fargate for a single table.", "StartAt": "requested_table", "TimeoutSeconds": 3600, "States": { "requested_table": { "Type": "Task", "Resource": "arn:aws:states:::ecs:runTask.sync", "Parameters": { "LaunchType": "FARGATE", "Cluster": "data-sync-cluster", "TaskDefinition": "arn:aws:ecs:<region>:<awsid>:task-definition/<taskname>:<family>", "NetworkConfiguration": { "AwsvpcConfiguration": { "Subnets": [ "<subnet-1>", "<subnet-2>" ], "AssignPublicIp": "DISABLED" } }, "Overrides": { "ContainerOverrides": [ { "Name": "data-sync-container", "Command.$": "$.embulk_run_args" } ] } }, "End": true } } }
ポイントは ContainerOverrides となります。ここで Fargate に渡す引数を指定しています。
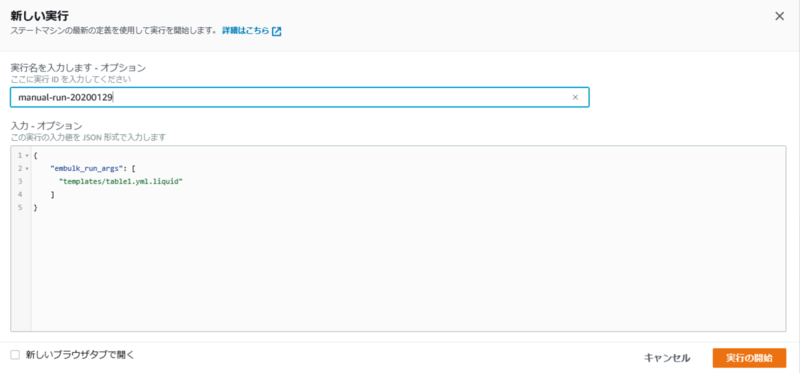
Command.$ および $.embulk_run_args は Step Functions の入力で配列を扱うための記法です。例えば、table1 をエクスポートするための設定が記述された table1.yml.liquid を読み込ませたい場合、
{ "embulk_run_args": [ "templates/table1.yml.liquid" ] }
のような入力をステートマシンへ渡すと、実際の Command には [ "templates/table1.yml.liquid" ] が入ります。
Fargate
処理としては単純で、ステートマシン経由でコンテナに与えられた引数をそのまま embulk run への引数として渡しているだけです。
引数として以下を渡すことが多いです。
- Embulk の設定ファイル (YAML) のパス (必須)
- 差分ファイルのパス (任意)
差分ファイルは Append 型のテーブルで使います。以下が詳しいですが、Append 型にすると前回実行時からの差分レコードを TreasureData に送信することができます。
https://github.com/treasure-data/embulk-output-td#modes
なお、差分ファイル指定時はコンテナの追加処理として
- Embulk 実行前に S3 へ差分ファイルの有無を確認して、あればコンテナ内にダウンロード
- Embulk 実行後に差分ファイルを S3 へアップロード
ということを行っています。
通知まわり: CloudWatch Events/SNS/Lambda/Slack
Step Functions のマネジメントコンソール上で、ステータス変更時に SNS を飛ばすための CloudWatch Events 設定が可能です。
設定内で特定のステータス時のみ通知を飛ばせるようにできるため、今回は TIMED_OUT/FAILED 時に限定しています。
2020/01 現在、残念ながら Step Functions からの SNS は AWS Chatbot に対応しておらず、Slack 通知したい場合は別途 Lambda 等で対応する必要があります。
Tips
Fargate or AWS Batch
Fargate ではなく AWS Batch を使うという案もありましたが、タスクの実行まで数分~数十分かかることがあるという点が気になりました。
https://techblog.timers-inc.com/entry/2019/08/06/aws-batch-lambda-ecs-comparison
実行までの所要時間が気にならなければ高機能なワークフローが構築できるので、 AWS Batch も検討に入れてよいと思います (とはいえ、Step Functions でもそれなりのワークフローが作れてしまう…)。
多重起動の防止
CloudWatch Events でスケジュール起動する以上、多重起動してしまう可能性が拭いきれません。 https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/CWE_Troubleshooting.html#RuleTriggeredMoreThanOnce
今回、コンテナ実行時 S3 にロックファイル (中身は空) をアップロードすることで簡易的に多重起動の防止を行っています。ロックファイルが存在していれば多重起動しているとみなし、コンテナ処理は行わせないようなイメージです。
TreasureData 送信時に DateTime が UTC に変換されてしまう
Embulk の out 設定に default_timezone: 'Asia/Tokyo' を追加することで解消できます。
むすび
Fargate を使って Aurora のデータを TreasureData へ送る方法について紹介しました。
Step Functions は名前の通り「複数の関数」を組み合わせて使うことを想定されています。今回は 1 コンテナのみでしたが、大きな処理になってくると 1 コンテナ (関数) における責務も大きくなりがちなので、小さく分割して Step Functions でつなげて使う、といった考え方ができそうです。
参考
- https://github.com/embulk/embulk
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/tutorial-scheduled-events-schedule-expressions.html
- https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/CWE_Troubleshooting.html
- https://github.com/treasure-data/embulk-output-td
- https://qiita.com/airtanker/items/25b4031e441600dae430
- https://blog.tkzwtks.net/entry/2018/12/22/191530
- https://techblog.timers-inc.com/entry/2019/08/06/aws-batch-lambda-ecs-comparison