
インフラチームの住吉です。 オープンワークでは今期よりSRE留学という制度が始まりました。 SRE留学を通じて感じたことやどんなことをしたのかを共有したいと思います!
SRE留学とは
端的にいうとwebアプリチームの人材がインフラチームに移動し、二つの領域の知見を得ることによって現在問題意識のあることの解消やより良い開発体験、効率的な運用を実現しようというものです。
詳しい背景や目的は下記のようになっています。*トイル=自動化可能な繰り返される価値のない手作業のことです。
SRE留学は応募制になっており、今回第一号として私がSRE留学させていただきました。
SRE留学に応募したきっかけ
少し私がSRE留学に応募したきっかけについて話そうと思います。
主に理由は2つです。
- インフラに興味があったから
- 人材価値の向上
インフラに興味があった
今までwebアプリの開発をするにあたって私の場合、全体構造を掴めている方が理解が早くなるなと感じることが多くありました。 webアプリの開発範囲の知識だけで大体の開発はできますがものによってはサーバー,ネットワークの構成がわかっていたりする方が具体的なイメージが湧きやすく、個人的に開発が楽になりそうだと思っていました。
インフラに興味があるといった点ではシンプルに面白そうというのもあります。 個人的に休みの日にawsのリソースをterraformでコード化してみたりしていたのですが、やっぱり現場レベルでやってみたくなりますよね!
人材価値の向上
近年ではDevOpsやSREといった領域を跨いだ人材の価値が上昇していることもあり、今後のキャリアを考えたときにもインフラの経験が欲しいと考えていました。
実際にやったこと
今期私が取り組んだものは二つです。
ファイルアップロード機能のアーキテクチャ改善
SRE留学ではトイル削減を行っていくのが主な目的はあるのですが、そもそもインフラの知見がない状態でいきなり自動化プログラムを組むのはハードルが高いですし考慮漏れなどでバグを生むこともあり得えます。 ですので直近のインフラの課題としてファイルアップロード機能のアーキテクチャ改善というものがあったのでインフラの知見を得るといった意味でこちらに着手しました。
また、こちらの機能はインフラの構成を変更するだけでなくwebアプリのコードを修正する必要もあったのでwebとインフラ両方の作業があり、SRE留学としては打って付けでした。
概要
オープンワークでは企業と転職活動中のユーザーのメッセージをやり取りする機能があり、その中にファイルを共有する機能があります。
このファイル共有機能ですがファイルの安全性確認を行っており、ファイルをアップロード後安全性に問題がなければ企業に公開されます。
手順はざっくりとですが下記のような感じです。
- ファイルをアップロード
- アップロードされたファイルの安全性を確認
- 確認結果をDynamoDBに追加
- webのサーバーが毎分バッチを起動してDynamoDBの確認結果を取得
- 確認結果をもとにファイルを公開していいかチェックし、問題なければ公開
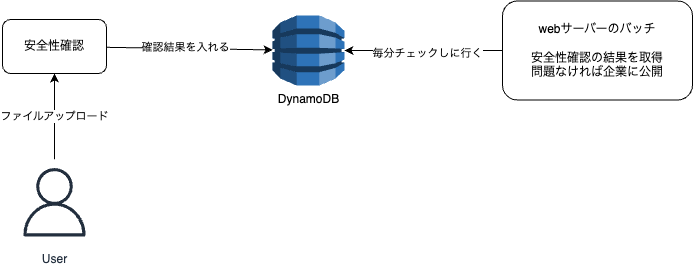
この機構でも機能としては問題ないのですが、2点問題があります。
- Fargate上で毎分のバッチを起動することになるのでコストがそれなりにかかっていること
- バッチの起動時間の問題で最大1分間反映までに時間がかかってしまうこと
上記の問題を解消するというのが今回の改善目的です。
改善
改善の方針としてはDynamoDBにwebサーバーから確認結果を取得しにいくのではなく、DynamoDBにデータが入ったらAWSサービスからweb側のAPIを叩いてもらうというものです。状態変化をトリガーに起動するいわゆるイベント駆動アーキテクチャと呼ばれるものです。DynamoDBにはDynamoDB Streamsというサービスがあり、状態変化を検知してくれるので今回はこちらを使って実現しました。
手順はこのようになりました。
- ファイルをアップロード
- アップロードされたファイルの安全性を確認
- 確認結果をDynamoDBに追加
- DynamoDBへのデータ追加を起点にDynamoDB streamsへデータを転送
- lambdaがstreamsからデータを取得し、webサーバーのAPIを叩く
- API側に送られてきた確認結果もとにファイルを公開していいかチェックし、問題なければ公開
(lambdaからAPIを叩く間にも複数のサービスが存在しますがイベント駆動化とはあまり関係ないので割愛しています。)
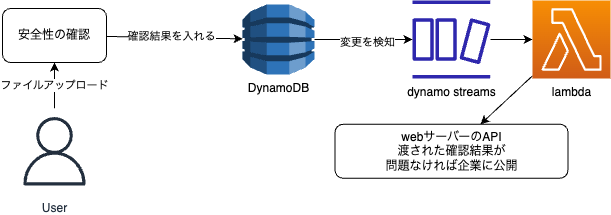
この機構に変更することでバッチのコスト削減をすることができ、イベント駆動化でニアリアルタイムでの反映が可能になりました。
トイルの削減
二つ目めはトイルの削減に着手しました。
概要
自動化したのはシステムエラーの調査を簡略化するというものです。 AWSではecs taskが停止した時の状態を取得してくれるAPIや実行履歴を取得してくれるAPIなど、原因調査に使えるAPIが提供されています。 これを使って実現します。
現状バッチ実行はecsのrun taskコマンドを使ってバッチコマンドを実行しており、そのバッチが異常停止したときにどのコマンドが落ちたかなどはslackに通知されています。 その通知がきてどんな問題が起きているのか?というのを調査し始めるのですが調査開始時点であたりがついていてくれると大変助かります。
なので今回はコマンドが落ちたことを通知してくれるslackメッセージにコマンド実行の失敗理由を記載した上で通知させてみる形で対応しました。
どうやったのか?
前提の話ですがecsのrun taskコマンドはstep functions上で動いており、run taskの実行終了や異常終了時の履歴がstep functionsに残っています。 そして既存のslack通知はsfnの失敗をトリガーに起動しているlambdaで実行しており、実行したstep functionsの実行arn(実行を一意に識別するもの)をlambdaに渡しています。
この構造が既にあるのでlambdaに渡ってきた実行arnから実行履歴を取得し失敗理由を特定します。 失敗理由はAWSのドキュメントに記載されているタスクの停止コードだったり、実行コンテナの終了コードから判断します。
判断ができたら適切な文言を作成し、slackのメッセージに含めて送信します。
before/after
before(左):特にメッセージはない状態
after(右):メッセージが追加されてエラー理由がわかる


これで大方のエラー理由がslack通知からわかり、調査開始時のまずなんのエラー?という第一ステップが省かれました!
留学してみてどうだったか?
シンプルな感想
シンプルな感想としては楽しかったです! 普段触らない領域のことをするのはなんだかわからないですがワクワクしました! 知見が増えるというのはやっぱりいいものですね!
それと同時にインフラの方々が普段運用されているシステム規模が思っていた以上に多く、ビックリもしました。 webアプリ側でもこんな機能あったのか?というようなことは多々あるのですが、知らなくても特段問題ないことが多いです。 ですが、インフラだと構成を把握してないとネットワークなどの問題でリクエストが捌かれないみたいなことが起きて即障害ということもありえます。 そういったことを防ぐためのドキュメンテーション力みたいなものが問われるなと感じました。
成長できたなと思うこと
大まかに下記のことについて理解を深めることができ成長できたと思います。
- インフラの構成の知識
- 障害が起きたときにどのように復旧させる
- 障害がなければ行うはずだった処理をどうやってリトライさせる
- AWSの知見
- AWSサービスそれぞれの特徴把握とどういったシナリオで使うのか
- AWSのCLIやSDKの使い方
- terraformのコーディング
- チームでのterraformの運用の仕方
- modulesの作成や使用の仕方
最後に
SRE留学を通して個人的な目的にあったアプリの全体構造を把握することによって開発がより楽に効率良くできそうといったところは感じることができました。 また、インフラチームとしても運用コストを下げる取り組みを推進できたように思います。
オープンワークではSRE留学のような開発効率向上や運用改善のための新しい取り組みを行っています。 このような文化にご興味がある方はぜひ弊社の求人をチェックしてみてください。 www.openwork.co.jp