
インフラチームの小川 (@tsubasaogawa) です。最近洗濯機を買い換えたので、洗濯の様子を夜な夜な窓から眺めては悦に浸っています。
先日、以下記事を書きました。 techblog.openwork.co.jp
そして今回は本番環境の話となります。主に以下 3 点について述べていこうと思います。
- 移行前後の構成と特徴
- 移行のポイント
- 移行の本番リリースで起きた問題
移行前後の構成と特徴
移行前
移行前は Elastic Beanstalk を利用していました。以下記事で構成の説明があります。 techblog.openwork.co.jp
特徴としては以下があります。
- Elastic Beanstalk で EC2 を管理
- web サーバーは ALB + AutoScaling で冗長化
- batch サーバーは単一の EC2 であり、サーバー内の cron で各バッチをスケジューリング実行
- 部分的に CloudFormation が使われているが、基本的にはマネージドコンソールから作成されている
- CDN は Fastly を主に利用しているが、一部のコンテンツでは CloudFront も利用
なお、web サーバーと batch サーバーは同じ Symfony のソースで構成されていました。batch に関しては Symfony の Console Commands を利用しています。これはコンテナ化しても同じです。
移行後
以下は概要説明のための簡単な構成図となります。コンピューティングリソースを ECS + Fargate に移行し、それ以外の構成は基本的には変わりません。
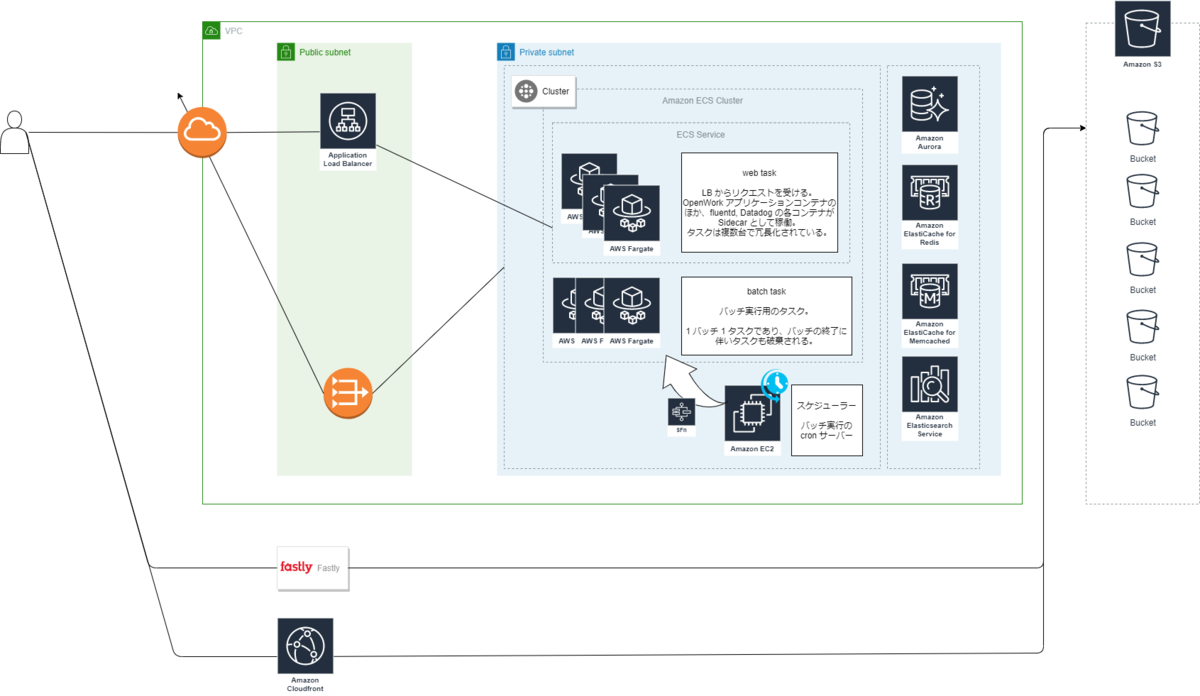
特筆すべき点としては以下があります。
- 大きく分けて web と batch 2 種類の Fargate Task (no Spot) が稼働している
- Apache を動かすかどうかでタスク定義を分けている
- 2 つの Task は同じ ECS Cluster 配下で実行
- web task に関してはさらに ECS Service で管理
- batch 実行用のスケジューラーは Elastic Beanstalk + EC2 で稼働
- EventBridge を使えばフルマネージド化できるが、少なくとも 1 回起動する という EventBridge の仕様を吸収するのが (工数的に) 難しい
- つまり重複起動することがあり、実装側で冪等性や同時実行耐性を担保しなければいけない
- EventBridge を使えばフルマネージド化できるが、少なくとも 1 回起動する という EventBridge の仕様を吸収するのが (工数的に) 難しい
- batch 実行する際は Step Functions から RunTask させる
- ダイレクトに RunTask すると、Task の起動に失敗することがあるため (参考)
- 起動失敗時は Lambda でエラー内容を確認し、リトライすべきエラーであれば再度 RunTask するようにステートマシンを定義
- DB など一部を除き、すべてのリソースを Terraform で作成
移行のポイント
愚直に Dockerfile 移植をする
Elastic Beanstalk は設定ファイル (ebextensions) とプラットフォームフック (hooks) をもとにプロビジョニングを行います。これらの一連の処理をまるっと Dockerfile に転記すれば、事実上は「Elastic Beanstalk で動く EC2 と同じ環境」が Docker Image として構築できるはずです。
この「同じ環境」であることが、アプリケーションのコンテナ化を進めていく上で重要でした。例えばですが、移行前後で大きな環境差異があったりすると、アプリケーションで不具合が起きたときに原因特定するのが困難になります (OS 起因なのか、実装起因なのか、はたまた別のところにあるのか、など)。
Dockerfile 作成時においては「このパッケージ削れば軽くなりそう」とか「もっといい書き方できそう」などとついつい手を入れたくなったりするのがエンジニアの性ですが、ここはぐっとこらえて愚直に移植をすすめていきました。
落ちても影響の小さいバッチを前もってリリース
様々なバッチが cron でスケジュール起動しています。これらをコンテナ化して ECS で稼働させるにあたって、仮に落ちても影響の小さいバッチをいくつかピックアップし、先行的に本番稼働させました。
結果としてはこの試みがうまくいき、本番稼働させないとわかりづらい問題をリリースの前に洗い出せました。
負荷検証はしっかりやる
リリース日までかなり余裕のないスケジューリングではありましたが、そのような中でも負荷検証にはそれなりのリソースをかけて行いました。検証には k6.io を利用しました。
結果、新環境はレスポンスタイムがより遅くなっていることが明らかになりました。ミドルウェアの PHP を 7.2 から 7.4 へアップグレードすることで、レスポンスタイムは大きく改善し移行前より優れた値となりました。PHP のアップグレードは当初計画していたもので、PHP のパフォーマンス改善に助けられたような形になりました。
負荷検証を優先した分、リリースに間に合わず取捨選択したタスクもいくつかありましたが、それを踏まえてでも行うべきアクションだったと思います。
移行の本番リリースで起きた問題
ファイルディスクリプタ枯渇
コンテナ化によって OS のファイルディスクリプタが小さくなってしまいました。
ファイルディスクリプタが小さくなると、大量のファイルをオープンしたときに Too many open files エラーが発生してしまいます。あるバッチ処理でこの問題が発生し、処理が途中で落ちてしまいました。
対応としてはタスク定義の ulimit を大きくすることで解消しました。 ebc-2in2crc.hatenablog.jp
本来はステージング環境以下で発見すべき問題だったのですが、バッチの扱うファイル数が本番環境とそれ以外とで大きな差があり、テストで見つけることができませんでした。テストにはまだまだ改善の余地があります。
FireLens で送ったログが滞留・欠損
アプリケーションのログは、標準出力から AWS FireLens を経由して Sidecar の Fluentd へ送る構成としていました。ここで、大量のログ (毎秒 400 文字 x 300 行) 程度を標準出力へ送ったときに、どうやら Fluentd に渡るところでログの滞留が起きているようでした。 問題は、アプリケーションコンテナの終了間際にこれが起きると、場合によってはログが欠損するという点です。つまり、ログを捌き切る前に Task が終了してしまうということです。
ここで、Fluentd の flush_at_shutdown が true の場合、Fluentd に渡っているログはすべて捌き切ってから終了します。時間がかかりすぎると ECS から SIGKILL されてしまいますが、KILL されていないにも関わらずログが欠損するということは、 Fluentd にログが渡っていない可能性があります。つまり、前段の FireLens で滞留が起きているのではないかと考えられます。
対策として、FireLens は利用せず Sidecar の Fluentd へ直接 TCP でログを送るようにアプリケーションを改修しました。これによってログの欠損は起きなくなりましたが、未だに信頼性という点では課題があるので、近いうちに手を入れたいと思っています。
NAT の料金が高騰
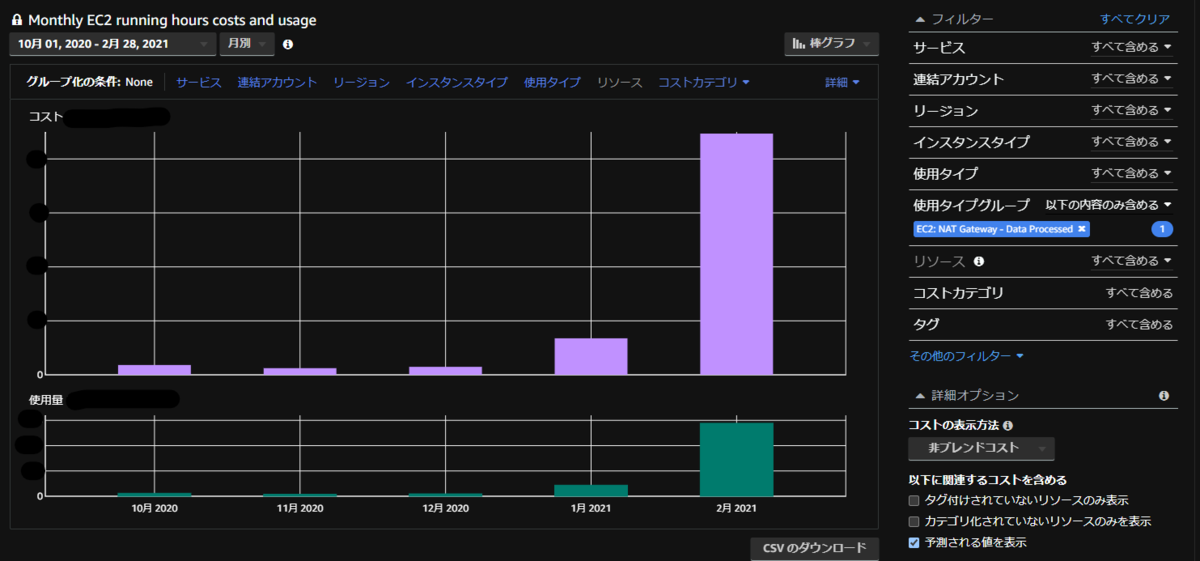
リリース後、NAT Gateway の料金が大幅に増加しました。 原因は、Private Subnet に置いた ECS Task が ECR から Container Pull する際にインターネットを介することでした。以下記事と同様のケースです。 techdo.mediado.jp
VPC Endpoint 経由で ECR へアクセスすることで解消しました。
Googlebot からの 400 Bad Request が急増
web のリリースにおいては、www.vorkers.com の向き先を新しいロードバランサーに切り替えるという方法をとりました。 これによる影響なのか、切り替え後に Googlebot からの一部のアクセスにおいて 400 エラーが多発しました。クロールを拒否し続けると Google の検索結果に影響することがあるため、優先度を上げて調査したものの原因はわからないままでした。結果的に影響はなかったので良かったのですが、心臓に悪かったです。
気になっているのは、
- Googlebot から正常なリクエストもされていた
- 400 となったリクエストをみてみると、www.vorkers.com ドメインではなく背後のロードバランサー宛へリクエストしていた
という点です。
その他、起きた問題
箇条書きで列挙します。
- Terraform で本番 Route53 の CNAME を書き換えるときに
InvalidInputエラー- フェイルオーバーレコードの set_identifier を変更することで生じる?
- 恐らく https://github.com/hashicorp/terraform-provider-aws/issues/7998 を踏んだと推測
- 仕方がないので手動で Route53 のレコードを変更して対処
- RunTask した Fargate が想定よりも小さい CPU/Memory で動いていた
- タスク定義の CPU/Memory が使われる想定だったが、一部のスクリプトからはより小さい値で Override した上で RunTask していた
- マネージドコンソールから ECS Service の設定を変更したら、Service の Fargate Platform Version が 1.4.0 -> LATEST になった
- 特に設定変更していない箇所の値が変わってしまった
- リリースした時期はまだ LATEST = 1.3.0 だったため、実質的にバージョンが下がってしまった
- Service へのデプロイは CodeDeploy による Blue/Green デプロイを採用していたため、CodeDeploy 側で設定変更をデプロイするのが正しい
- チームのマネジャーが本番リリース当日に健康診断に行って不在
- リリース日が当初から変更されたことなどが影響して見事ブッキング
- もちろんですが私も了承の上のことです
むすび
Elastic Beanstalk で動いていた Web アプリケーションをコンテナ化して ECS Fargate 上で稼働させました。
規模の大きい改修であり、リリース後にはいくつか問題が起きてしまいました。当然ながら問題を起こさないことが一番ですが、問題が起きた場合にどう動けば UX への影響を最小限にできるか、という観点が非常に重要に思います。
無事コンテナ化はされたものの、Cloud Native への旅はようやくスタート地点です。社内向けの開発環境にも課題がたくさんあります。 OpenWork サービスの信頼性をインフラから支えていきたい方、大募集です。