
こんにちは。Webアプリエンジニアの生永です。
Webサービスを作っていると、当初は問題なかったのに次第にパフォーマンス面でなかなか遅くなっていくことがあると思います。弊サービスにおいても、パフォーマンス面の問題がレスポンスまでの時間、レイテンシとして現れてきています。そんな問題の対応を最近2件行ったため、問題とその対応の解答例をご紹介します。
記事のタイトルにも記載している通り、今回は2つともSQL改善がテーマになっています。
※お断り 本記事内で紹介されるクエリやデータ等に関しては多少加工され実際のものとは異なる場合がございます。
まずは問題を見つけるところから
弊サービスではDatadogを活用して、レイテンシを測定しています。 Datadogのダッシュボードでルートごとにレイテンシを確認できるようにしています。
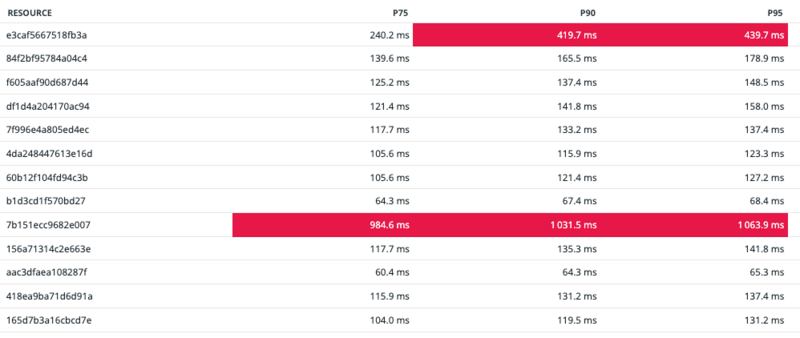
この中から、日頃のリクエスト数やレイテンシ値、そしてビジネスレベルでの重要度を踏まえ、ルートごとに改善優先度を決めて対応することにしました。
今回は、「月内のスカウト可能通数の表示処理」と「未対応の求人応募者の通知処理」をピックアップして対応しました。
Case1 大きくなったテーブルの検索速度劣化
問題の分析
「月内のスカウト可能通数の表示処理」において著しい速度劣化が確認されていました。
弊サービスでは、企業が転職を考えているユーザに対して直接スカウトを送り、アプローチをかけることができます。ご利用いただいている企業に月ごとにスカウト可能通数を付与し、限られたスカウトをユーザに送っていただくようにしています。
この月ごとのスカウト可能通数の残りを算出し、表示する処理が遅くなっていたのです。
まず、Datadogのルートごとのトレースを確認してみると、以下のような状況でした。
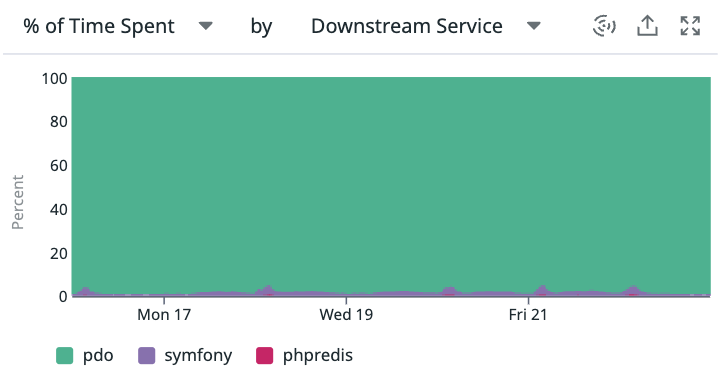
pdo!圧倒的にRDBで時間を食っているようです。
より詳しく見ると、以下のようなクエリで時間がかかっていることがわかりました。
SELECT
count ( s.id ) FROM scouts s
WHERE s.company_id = COMPANY_ID
AND s.created_at >= THIS_MONTH_FIRST_DATE
AND s.created_at < NEXT_MONTH_FIRST_DATE
当月の企業のスカウト通数を数えているようです。この数と企業に付与されているスカウト可能通数の差から残りの数を算出しているみたいです。
ちなみにscoutテーブルを確認するとidとcompany_idにはそれぞれインデックスが設定されていました。
解決策の検討
今回、解決策として検討したのは4パターンでした。 1. SQL or インデックスの見直し 2. クエリ結果のキャッシュ利用 3. テーブル設計の見直し 4. 不要なレコードを削除 別の場所に移管
上記の解決策はDBアクセスにまつわるパフォーマンス改善です。そして、それぞれの解決策の影響範囲や対応コストから考えるにこの順序で検討していくのが一般的ではないかなと考えています。
この中で今回は結果的に「1. SQL or インデックスの見直し」となりました。
まずはEXPLAINでクエリの評価状況を見てみました。

クエリは至ってシンプルであるため、クエリの構造を工夫するのは難しそうです。
一方、ここで注目したのはtypeがrefであること。
type=refとは、PRIMARY KEY、UNIQUE KEYでないインデックス(ユニークでないインデックス)を使って等価検索を行っていることを示しています。これは通常ではconstやeq_refの次に速い処理とされ、無視しても良いとされています。しかし、データ量が増加しパフォーマンスに影響を出しているからには見直していきましょう。
EXPLAIN ANALYZEでより詳しく見てみました。
-> Aggregate: count(s.id) (actual time=1018.301..1018.301 rows=1 loops=1)
-> Filter: ((s.created_at >= THIS_MONTH_FIRST_DATE) and (s.created_at < NEXT_MONTH_FIRST_DATE)) (cost=118940.61 rows=77497) (actual time=865.052..1015.899 rows=45327 loops=1)
-> Index lookup on s using idx_company_id (company_id=COMPANY_ID) (cost=118940.61 rows=697616) (actual time=0.276..984.752 rows=356493 loops=1)
詳しく見るとrefはこのインデックスで評価された行を全て読み取りを行っていることがわかります。カーディナリはまだまだ荒いですが企業IDのインデックスを使用して絞り込めているみたいです。企業IDで紐づいたスカウトデータを全て読み取った後に期間をWHERE句で絞る順番でクエリを評価していることになります。これでは、企業ごとのデータ量が増えれば増えるほど処理速度が遅くなっていってしまうでしょう。
ちなみに気になったので期間を絞ることをやめてみるとどうなるかも確認しておきます。
-> Aggregate: count(s.id) (actual time=115.992..115.993 rows=1 loops=1)
-> Index lookup on s using idx_company_id (company_id=COMPANY_ID) (cost=71080.62 rows=697616) (actual time=0.034..97.014 rows=356493 loops=1)
こちらの方がテーブルを全体的に見なければならないはずなのにより速く結果が得られました。やはり期間を絞り込むWHERE句が悪さをしているようです。
refより速い処理としてはconstやeq_refですが、クエリの中で定数やユニークな条件を指定するのは難しそうであったため、あえてrangeで処理ができないかを考えました。type=rangeとは、インデックスを使った範囲検索であり、行を選択するためのインデックスを使用して、特定の範囲にある行のみが取得されます。上述の通り、特定範囲の検索のみをしたいという場合には有効なのではないかと考えてみました。
company_idとcreated_atで複合インデックスを設定し、試してみると......

想定通り、type=rangeになっており、なおかつExtraを見るとインデックスを使用した検索になっているみたいですね。
-> Aggregate: count(s.id) (actual time=27.279..27.279 rows=1 loops=1)
-> Filter: ((s.company_id = COMPANY_ID) and (s.created_at >= THIS_MONTH_FIRST_DATE) and (s.created_at < NEXT_MONTH_FIRST_DATE)) (cost=18019.71 rows=88956) (actual time=0.047..24.613 rows=45327 loops=1)
-> Index range scan on s using idx_company_id_created_at (cost=18019.71 rows=88956) (actual time=0.045..16.685 rows=45327 loops=1)
EXPLAIN ANALYZEでもより速くなっていることを確認できました。
最後にインデックスを新たに設定する場合に、気をつけなければならないことだけ確認しておきましょう。
テーブルにインデックスを設定することでそのテーブルに対するINSERTやUPDATEといった更新系の処理が遅くなると言われています。
この部分を確認しましたが、影響はほぼありませんでした。
スカウトを送信する前に残りのスカウト可能通数をチェックするために同じクエリを叩いているため、むしろアプリケーションレベルで見ると、処理が速くなるということを確認しました。
効果の確認
グラフで見ると効果が歴然ですね!嬉しい限りです。
インデックスの見直し前後で「月内のスカウト可能通数の表示処理」を比較するとおよそ10倍の処理速度にすることができました。
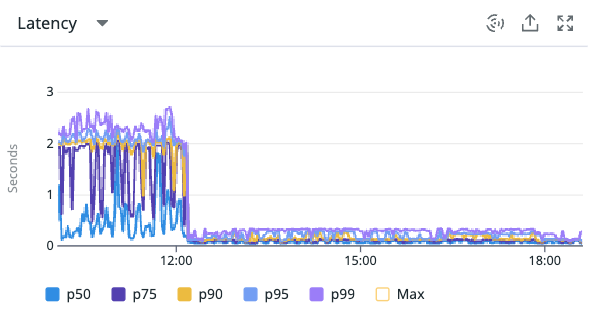
また、スカウト送信処理に関しても以下の通り、送信可能数チェックが速くなったことにより安定することが確認できました!
ですが1秒かかってしまうあたりまだまだ改善の余地はありそうです。
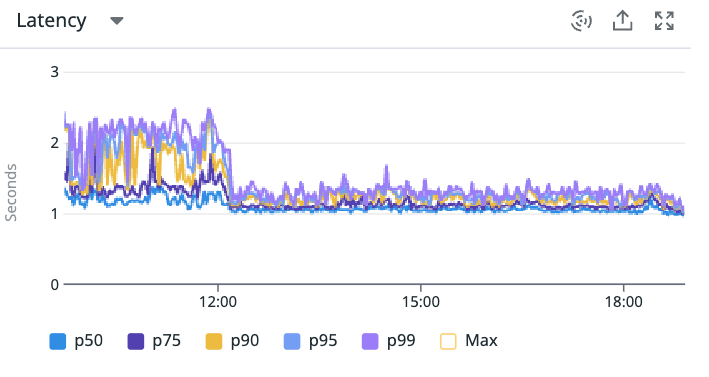
今考えれば以下のようにSQLを修正するとより効果を高めることができたと思います。
比較演算子による二つの式で条件指定した場合、オプティマイザーはインデックスに複数回の操作をする一方、BETWEENはオプティマイザーは指定範囲のインデックスノードを1回の操作で比較できるとのことです。
改善の道は長い...
WHERE s.created_at
BETWEEN
THIS_MONTH_FIRST_DATE
AND DATE_SUB(NEXT_MONTH_FIRST_DATE, INTERVAL 1 DAY)
Case2 複数テーブル結合を伴う検索速度劣化
問題の分析
「未対応の求人応募者の通知判定処理」においても速度劣化が見られました。
今回はルートというより特定の処理が遅いというパターンです。
求人に応募してくださった応募者が未対応のまま放置されてしまわないようにチェックをかけている処理にあたります。
どういった内部処理状況なのかDatadogで確認してみました。この辺はCase1と同じため、割愛します。
調べた結果、以下のスロークエリの影響が大きそうでした。
SELECT ja.id FROM job_applications ja INNER JOIN job_application_details jad ON ja.id = jad.job_application_id INNER JOIN messages m ON ( m.user_id = ja.user_id AND m.company_id = jad.company_id ) LEFT JOIN scouts s ON ( s.message_id = m.id ) WHERE m.company_id = COMPANY_ID AND m.from = FROM_USER AND s.id IS NULL GROUP BY ja.id
このSQLは既に対応済の求人応募者を抽出するクエリでした。この結果と求人応募者全体の差で「未対応の求人応募者」を判定しているようです。
それぞれ結合に使用している部分にはインデックスは設定されていました。
解決策の検討
Case1同様にEXPLAINをしてみます。
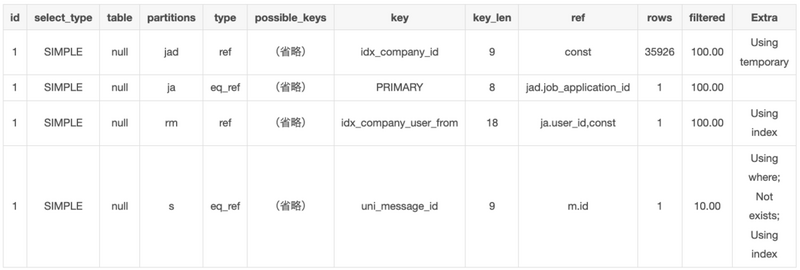
ここで注目したいのはUsing temporaryです。
Using temporaryはMySQLの実行計画中に内部で一時的にテーブルを作成してそこに結果を保持する処理が発生していることを示しています。取得するデータ量が設定したメモリのバッファを超えてしまう場合に発生し、クエリパフォーマンスが悪いとされています。
Using temporaryの対策としては、単純にMySQLのメモリのバッファサイズを引き上げるという手があります。
tmp_table_size max_heap_table_size の2つの設定値を引き上げます。(デフォルトではどちらも16MBです。)
ですが、今回はクエリを見直すことで解決できそうなためそっちで試してみましょう。
ちなみにUsing temporaryはUsing temporary; Using filesort;として現れることが多いです。これはGROUP BYを使用している場合に現れることが多く、一時テーブルを作成後にその中でデータを改めてソートをしているため、よりパフォーマンスが悪いとされています(Using filesort単体で現れる場合はまた異なる理由です)。今回は現れていませんが、クエリを見るにGROUP BYがなくとも成立しそうであるため、不要な処理も無くしてしまいましょう。
改めて問題の箇所を確認します。
JOIN句でjob_application_detailsテーブルを内部結合をしようとしている際に一時テーブルが発生しているようです。
job_application_detailsテーブルの結合というよりJOIN句の評価時点で保持しなければならないデータ量が全体的に多いとも考えられます。
一方でSELECT句とWHERE句を見てみるとSELECT句にはjob_applicationsテーブルのデータのみ、WHERE句では、messages、scoutsテーブルのみがあればよさそうです。複数のテーブルが結合されていますが、それぞれの処理は分かれているため、必ず全てのテーブルを一度に結合する必要はなさそうです。
それらを踏まえたうえで、作成したクエリが以下のものです。
SELECT ja.id FROM job_applications ja INNER JOIN job_application_details jad ON ja.id = jad.job_application_id WHERE EXISTS ( SELECT 1 FROM messages m LEFT JOIN scouts s ON ( s.message_id = m.id ) WHERE m.from = FROM_USER AND s.id IS NULL AND m.user_id = ja.user_id AND m.company_id = jad.company_id ) AND jad.company_id = COMPANY_ID
相関サブクエリを使うことでメインクエリのJOIN句評価時点で保持しなければならないデータ量を減らすことを試みました。
また、job_applicationsテーブルに対して結合するパターンを内部結合のみにすることでGROUP BY ja.idを不要としています。
INNER JOINとEXISTSによる相関サブクエリはともにデータの絞り込みの効果を得ることができます。一般的には相関サブクエリよりもINNER JOINの方がパフォーマンスが高いとされていますが、ここはあえて相関サブクエリにすることを選択しています。
見直し後のクエリでEXPLAINを確認してみます。

Using temporaryがなくなってます。一方、FirstMatch(ja)が追加されています。これは相関サブクエリが実行計画に現れているみたいです。セミジョインのFirstMatchが適用されているということみたいですが、問題なさそうなため、今回は説明は割愛します。
効果の確認
それぞれのクエリのレイテンシを見てみると以下の通りでした。おおよそ2/3以下に抑えることができているようです。
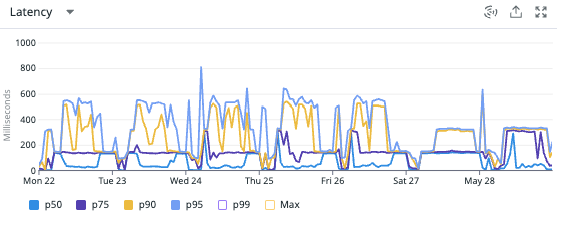
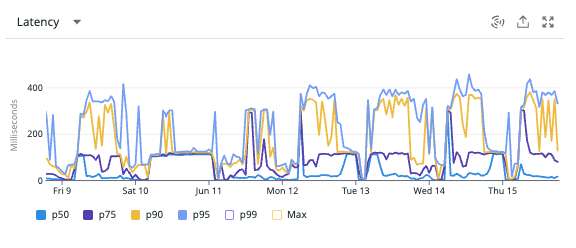
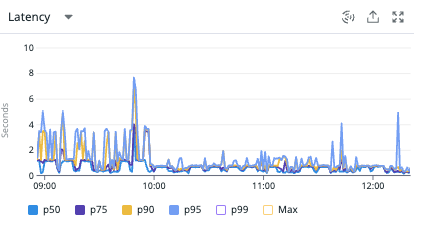
この判定処理を使用しているルートのレイテンシも確認してみると2~3秒かかりがちだったところが大体が2秒以下に抑えることができるようになっているようです。これは大きい。
最後に
以上、今回はスロークエリによって引き起こされるパフォーマンス劣化の改善をご紹介しました。このようにDatadogなどを活用したアプリケーションの監視、改善の検討、実施までを一貫して対応しています。この他まだまだ改善ポイントは多く存在しています。また、今回対応した箇所も改善の余地がありますし、今後アプリケーション規模が拡大していくことでまた別の改善方法に取り掛かる必要が出てくるでしょう。
弊社ではエンジニアを募集しています。アプリケーションの規模にあったパフォーマンス改善に興味がある方、私だったらもっとこんな解答をしてみるよ!という方、ぜひ一緒に働いてみませんか?
この記事を読んで少しでも興味を持った方は、ぜひ採用サイトを覗いていただけると嬉しいです。 www.openwork.co.jp