
Webエンジニアの入江です。 リモートワークしているのですが、部屋が寒くて、こたつでお仕事したい今日この頃です。
ブログ投稿のハードルを下げたいので、ライトな記事も投稿してみようかと思います。
弊社のエンジニアは、主に5〜6個のプロジェクトチームに分かれて業務を行っています。 それぞれがtoB/toC、インフラ等別々の領域で機能開発を行っており、障害対応もそれぞれのチームが自律的に行っています。
今回は直近行った障害通知に関する改善を2つご紹介します。
前提:エラーログの取り扱い
エラーログは、Slack(速報通知)、S3(長期、保存用)、datadog(短期、検索用)にそれぞれ独立して保存されています。

改善ポイント
1.担当プロジェクトの振り分け面倒問題
OpenWorkには様々な機能があるため、機能毎に大まかに担当チームを決めています。
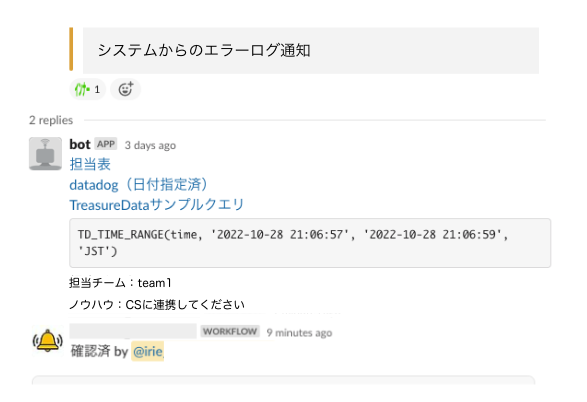
業務時間中は担当チームが障害通知に気づいて対応を始めますが、夜間休日に発生したエラーは専属メンバーが一次対応を行っています。致命的なエラーは現状ほとんどないのですが、エラーが忘れられないようにするため担当チームにメンションを飛ばすようにしていました。保守担当チームはスプレッドシートで管理しているのですが、都度担当チームを探しに行くのは手間がかかっていました。 また、業務時間中でもMTGが連続したり、作業に集中していたりすると通知に気が付かないこともあります。
そこで、Slackへのエラー通知をトリガーにスプレッドシートを検索してスタンプをつけるように設定しました。 既存の仕組みは変えず手軽にできる範囲で対応したので、非効率な感は否めませんが以下のような仕組みにしました。
- 絵文字リアクションで対応するプロジェクトにメンションされるSlackワークフローを構築
- エラー通知に、ヘッダ情報として機能名を付与
- 機能名を照合して担当チームの絵文字リアクションを付与するAPIをGASで構築
ついでにスプレッドシートに対応ノウハウや緊急度を書いてもらい、一緒に通知するようにしました。 これにより、エラー振り分けのコスト削減と、チームが入れ替わってもノウハウがすぐに手に入る状況が作れました。

2.無駄なエラー通知多すぎ問題
アンチパターンですが、ありがちだと思います。 基本的には、対応しないエラーは通知しないようにします。 ただ、中にはシステム上の制約等で「すぐには対応しないけど頻発したら何らかの対応を検討」のようなエラーもあったりします。
弊社ではdatadogにログを流すようにしているのですが、以下のような修正を入れることでエラー通知を減らすことができました。
- ログレベルを下げてdatadogのみにログを流す
- datadogでエラー件数を監視し、しきい値を超えたらエラーとしてslack通知する
datadogを使いこなしている方にとってみると当たり前のように感じるかもしれませんが、盲点でした。 datadog、もっと使いこなしていきたい・・・。
さいごに
小手先の改善ですが、得られた効果はそれなりに大きかったので、事例としてご紹介させていただきました。 ユーザや顧客の課題解決はもちろんですが、自分たち自身の業務改善にも積極的に取り組んでいきたい所存です。