朝夕の寒気が身にしみ、ふと歩けば日だまりが恋しく、舗道に散る落葉に冬を想う季節になってきました。
巷ではインフルエンザも流行っており、消費税も増税したので、日本の消費も冷え込んでしまわないか心配な今日このごろですが、最近プロジェクトとして機械学習環境をGoogle Cloud Platform(GCP)上で構築するプロジェクトを進めているので、その紹介をしたいと思います。
自己紹介
新卒でメーカー卸に就職し、社内SE的なことをやっていました。型番から製品情報をインクリメント検索するJavaScript実装したり、売上の帳票データからVBAでバーコード発行システム作ったり、企業サイトのリニューアルをCMSでやったりしてました。
その後某ポータルサイトの求人領域を担当する子会社で、インフラチームにジョインしてRedisやSolr入れたり、Zabbix入れたりして、求人サイトの運営や開発をしていました。
そして現職では、AWS周りやったり、GCP周りやったり、Elasticsearchやったり、求人系やML系プロジェクトをやっています。
ここでは触れないこと
データレイク的なこと
ML-Opsの文脈だと、データをどこから持ってくるかのデータエンジニア領域も含まれるケースもあると思うのですが、今回は対象外です。(どこからかデータが湧いてくると思ってください)
具体的な設定
まだ作りかけなので、具体的な設定はでてきません。ごめんなさい。
OpenWorkのいままでの機械学習環境
これまでもいくつか機械学習プロジェクトはあって、機能化もしているのですが、その時その時で採用技術も異なり、管理運用方法も異なっていたので、保守工数が増えがちでした。
またリリースするのに、データサイエンティストだけでなく、エンジニアの工数も利用するので、複数名のリソースを確保する必要があり、データサイエンティストの人が改善したい!と思っても、エンジニアのリソースが足りないので改善できない!といったこともあったりなかったりしました。
なぜML-Opsが必要なのか
モデルは一回作って終わりではありません。ビジネス課題に対して、開発サイクルを回し続けて、精度を保つ必要があります。
例えば、
- サイトの新しい施策を実施したところ、ユーザの行動が変わってしまった
- 市場動向が変化して、予測値が適切なものではなくなってしまった
など、データの変化に合わせて、学習を継続的に実施する必要があります。
また機械学習分野の発展は目まぐるしく、毎年のように大きな技術革新が起こり続けているので、常に新しいアルゴリズムやパラメータを試し続ける必要があります。
そのためには、機械学習開発のビルド・テスト・リリースを、迅速に、頻繁に、確実に行えるようにする必要があります。
データサイエンティストドリブンな開発
そこで機械学習開発において継続的な改善サイクルを、エンジニアの運用コストをなるべく掛けずに、データサイエンティストドリブンで実施できる環境を構築することを目標にプロジェクトを進めました。
弊社は事業ビジョンに「Working Data Platform構想」というものを掲げています。
この事業ビジョンを実現するために、データドリブンな開発を少人数で効率よく回せるようになることで、事業ビジョン達成への開発サイクルのスピードをあげていこうということです。
https://vorkers.jp/recruit/business
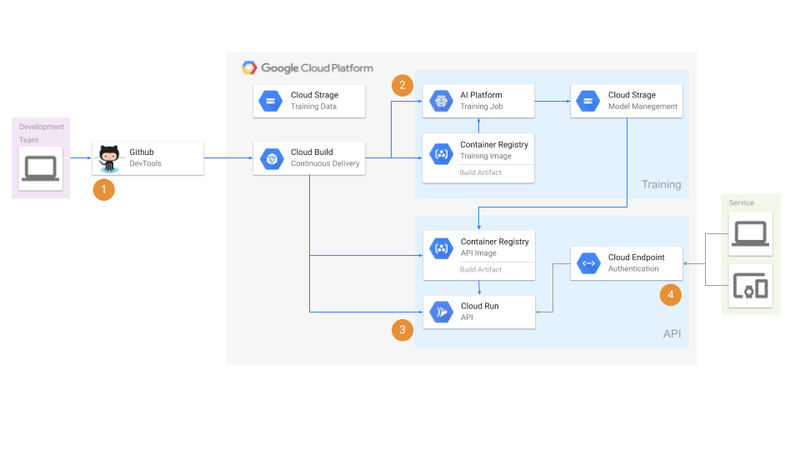
構成
フローの解説
1. GitHub Push
データサイエンティストがブランチ作成して、pushを行います。そうするとCloud Buildのトリガーが動きます。
大きく「学習部分」と「API部分」と「認証部分」でソースの構成を分けていて、特定のディレクトリ配下にpushするとそれぞれのトリガーが発火します。
トリガーをどの単位で分割するかも迷ったのですが、今回は「学習(Training)」と「API」と「認証(Authentication)」の大きなまとまりでトリガーを構成しています。
2. 学習(Training)
Cloud Buildのトリガーが発火すると、ビルドが実行されます。
学習ビルドでは、
- 学習データの取得
- 学習イメージのコンテナビルド
- AI Platform への学習ジョブの実行
- 生成したモデルファイルをGCSへアップロード
を行っています。
コンテナのビルドではGoogleContainerTools/kanikoを利用しています。
うまくレイヤーを含めたイメージのキャッシュが行われるようにすることで、イメージを変更していない場合は短時間でこのステップが完了するようにしています。
これでモデルファイルが完成しました。
3. API
APIを作成するビルドでは、
- モデルファイルの取得
- APIイメージのコンテナビルド
- Cloud Runへのデプロイ
- Cloud Runへのサービスアカウントの権限付与(後述)
を行っています。
今回API部分は、Cloud Runを利用しています。
AI PlatformでもAPI化ができる機能が提供されていますが、利用できるフレームワークが、xgboost/tensorflow/scikit-learnに限られており、今回これ以外の仕組みを利用するのと、今後も様々なフレームワークを採用する可能性があるので、Cloud Runを採用しました。
4. 認証(Authentication)
認証のビルドでは、
- ESPイメージのCloud Runへのデプロイ
- OpenAPIのYAMLファイルをCloud Endpointsへデプロイ
- ESPイメージのCloud Runの環境変数にドメインをセット
を行っています。
Cloud RunをAWS上から呼び出すために認証機能を、Cloud Endpointsで実現しています。
Endpoints は Extensible Service Proxy(ESP)を API ゲートウェイとして使用しますので、ESPコンテナもCloud Runにデプロイするようにしています。
そのうえで、サービスアカウントを使用して、ESPがAPIイメージのCloud Runを呼び出せるようにしています。
この設定では、ESP がサービスに対するすべてのリクエストを傍受し、必要なチェック(認証など)を行ってから、該当するAPIを呼び出します。
こちらもワークフロー上に組み込み、OpenAPI形式のYAMLファイルをコード管理しているので、認証部分に変更があった場合は、pushすると自動的にCloud Endpointsへ反映されるようになっています。
ブランチ戦略
GitHub Flowに近いものを想定していますが、まだステージングやプロダクションに反映させる設定はできていないので割愛します。
イメージとしては、特定ブランチにマージすると、それぞれの環境でCloud Buildが発火するイメージです。
意識したこと
GitOps
CI/CDを構築するときに、起点を何にするかと言うことはとても重要だと思っています。
今回はKubernetesの文脈で使われることの多いGitOpsの考え方を取り入れて、GitHubを起点にしています。
Single Source Of Truth
GitOpsを考えるときに忘れてはいけないのが、Single Source Of Truthです。
Gitを唯一の情報源として、Infrastructure as Code(IaC)で作られたインフラのコード管理もワークフローに組み込み、ワークフロー上で構成管理することで、コードとインフラの対応関係を保ちつつ、コードの変更によって構成管理も行います。
本来ならKubernetesを使うと、YAMLで宣言的に管理できるのですが、今回は工数的な問題でKubernetesやGKEは利用していないので、必要なワークフローをCloud Build上に組み込みました。
手続き的な部分もできてしまったので、より宣言的な構成管理をしていくのが、今後の課題かなと考えています。
指標や再現性
機械学習モデルの開発は、通常の開発とは少し異なります。
通常の開発では、依存するデータなどを考慮しつつ実装を行い、さまざまなケースをテストしてリリースするというフローになりますが、機械学習モデル開発では、以下の点が難しい部分だと考えています。
- モデルファイルというある意味ブラックボックスなものを履歴管理する必要がある
- ブラックボックスなモデルファイルが学習データに依存しており、その学習データが流動的である
- 学習データ、インプット・アウトプットデータやパターンが膨大である
なので、実装や評価やテストが非常に難しいです。
指標
精度という意味では統計的な指標もありますが、最終的に最も重視した方がよいのは、やはりサイト上の指標だと考えています。
弊社ではサイト上でABテストできる仕組みがあるので、まずはその仕組をうまく利用し、既存のAPIと新規APIのコンバージョンなどの指標が比較できることを、第一段階として想定しています。
再現性と、学習データとモデルとソースコードの対応関係
今回のフローの中では、GitHubを起点にしているので、機能名やブランチ名を、各データファイルやコンテナのタグの命名規則に含めるようにしています。
機能名やブランチ名で対応関係を作ることで、過去のモデルが再現できるようにしています。
パフォーマンス
呼び出し側の実装もしているのですが、パフォーマンスを担保するように、APIの結果をRedisにキャッシュさせる予定です。
機械学習のオンラインAPIは、パフォーマンスが課題になることが多いと思うのですが、今回はそこまで動的な変化がない結果を返すAPIなので、とりあえずはこの手法でサイトのパフォーマンスにほぼ影響を与えずに、リリースができるはずです。
今後の課題
宣言的な構成管理をすること
手続きな部分ができてしまったので、より宣言的にしたいですね。
モデルの事前評価やCIを組み込むこと
サービスで動かせる状態にすることが最優先だったので、まずはサービス上でのABテストができる状態を目指しましたが、モデルの事前評価や実際のアウトプットのテストなども組み込んでいきたいです。
これを行うことで、より安全にモデルの更新ができますし、人では追えないデータの変化を検知できると、その学習データの差分から、なぜモデルがそのような結果を返すようになったのか、どの学習データが原因かという、モデルの説明責任を果たすことができると考えています。
学習ジョブの高速化
評価やCIをフローに組み込むためには、学習ジョブの高速化も必須と思っています。
学習ジョブの実行にAI Platformを利用しているので、GPU/TPUインスタンスの利用や、workerを利用した分散学習などの拡張も行っていきたいですね。
まとめ
- 機械学習の開発でML-Opsは大事
- 小さく始めるならCloud Buildでも色々できるのでおすすめ
- まだまだ発展途上の技術領域なので楽しい
ここまで読んでくださって、ありがとうございました!
We Are Hiring
最後に。
弊社では、事業ビジョンの「Working Data Platform構想」をともに開発していける仲間を募集しています。
気になった方は、以下リンクをクリックしてみてください!